




Make your code run faster with Perl's secret turbo module

Most modern processors are multi-core, yet Perl programs will typically run single-threaded on only one core at a time. Enter the Many Core Engine module - it makes it easy to run your existing Perl code in parallel across every core on your platform, and get a huge speed boost along the way.
Requirements
You’ll need to install the MCE module. The current CPAN Testers’ results show it runs on a wide array of platforms and Perl versions. You can install MCE via CPAN at the command line:
$ cpan MCE
You do not need to have compiled Perl with threads enabled in order to get the parallel processing benefits as MCE can implement parallel processing using child processes via fork, forks::shared, or threads::shared. By default MCE will check for the presence of a threads module, otherwise, child processes are created via fork.
Understanding MCE
MCE’s documentation describes its implementation as a “bank queueing model”. Essentially, MCE uses up to one worker per core on the host platform, and distributes work between them in “chunks”. A chunk is just collection of elements, such as an array slice or a several lines of a file. The workers will process each chunk in parallel. The actual “work” done by a worker is usually the execution of a Perl subroutine. This will become clearer in the example below.
Managing the distribution and assignment of chunks creates a small overhead: therefore MCE is most effective when you have a large number of of elements to be processed and the “work” being done on every element is more than a basic pattern match. In the testing for this article, I was data munging web server logs and found a 50% runtime reduction was common.
Getting started
The easiest way to get started with MCE is by using one of the 3 basic automation models that come with MCE. The basic models are drop-in replacements for Perl’s foreach, map and grep controls. The models automatically tune themselves - by default they use the maximum number of cores available on the host platform and select an optimal chunk size based on the number of input records and source type.
Let’s look at the grep model. The code below is standard Perl code; it opens an nginx access.log and prints the number of records in the log that were from a robot useragent:
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
open(my $LOG, '<', '/var/logs/access.log');
my $count = grep { detect_robot($_) } <$LOG>;
say scalar $count;
Let’s modify the code above to use the MCE::Grep model. The new code is below:
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
use MCE::Grep;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
open(my $LOG, '<', '/var/logs/access.log');
my $count = mce_grep { detect_robot($_) } $LOG;
say scalar $count;
The main changes here are:
- The “use MCE::Grep” line which imports the module
- Changing grep to “mce_grep”
- Removing the diamond operator from the filehandle ($LOG)
The other difference is that this code will run a lot faster than the first example. How much faster depends on the platform and the number of input records. In my testing on a quad core processor, I found that the MCE::Grep was consistently 100-150% faster, but with more cores I would expect this to increase further.
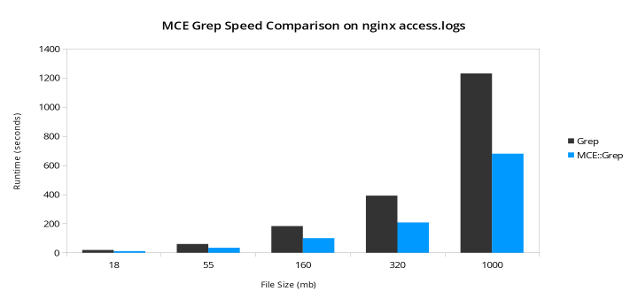
The other basic automation models MCE::Loop and MCE::Map work in much the same was as MCE::Grep.
Working with filepaths
MCE also provides a special “mce_grep_f” function for working directly with files (the function is provided for all MCE models, e.g. mce_loop_f, and mce_map_f). The “mce_grep_f” function requires a filepath argument:
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
use MCE::Grep;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
my $count = mce_grep_f { detect_robot($_) } '/var/logs/access.log';
say scalar $count;
This feature is broken in version 1.504 of MCE, however it’s easy to fix - just insert one line. The module’s author Mario Roy contacted me and kindly provided a diff. I’m told that this feature will be fixed in the next version of MCE. (EDIT: it is now fixed as of 1.509).
In testing the mce_grep_f function using the code above on a 55mb log file, I didn’t see a marked difference in performance compared to mce_grep, however there are reports of up to 4x speed improvement, so definitely explore this further.
Changing the number of workers
By default MCE initializes one worker per core. It detects the number of cores using the following methods:
- Linux: reads /proc/stat
- OSX/BSD: executes “sysctl -n hw.ncpu 2>/dev/null”
- Windows: uses the environmental variable: ENV{NUMBER_OF_PROCESSORS}
MCE also has platform-specific methods defined for Solaris, HP-UX and other systems. Assuming that MCE will correctly guess the number of processors, the only reason to change the default behavior would be to use less than 100% of the available cores. You can do this using the “init()” method:
use MCE::Grep;
MCE::Grep::init({max_workers => 3});
The code above uses MCE::Grep, but the same init() command is provided for all MCE models.
Changing the chunk size
When the source type is an array, MCE auto-calculates the chunk size based on the number of input records and workers available. You can override this, however in my testing I found that the auto-calculated chunk-size was nearly always optimal. Here is a typical result set, for processing a 55mb log file:
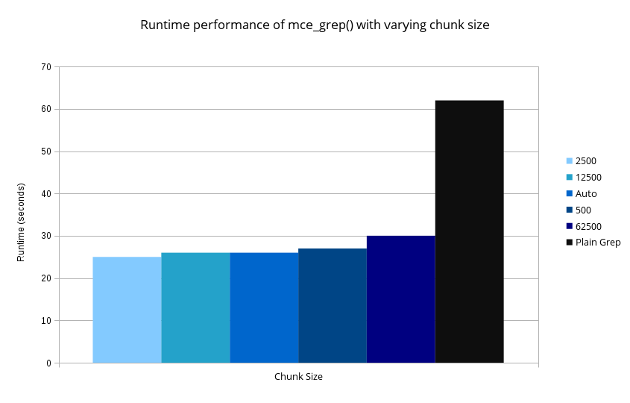
If the source type is a filehandle, the chunk size defaults to 2 (The module’s author Mario Roy has told me this will change in the next version, 1.506). Therefore you may want to override the chunk size to try to get better performance. You can do this using the “init()” method:
use MCE::Grep;
MCE::Grep::init({chunk_size => 500});
Because the management of assigning work chunks between workers carries a small overhead, the optimal chunk size would be the one that minimizes the number of chunk assignments, whilst keeping the workers equally busy. One factor that MCE does not take into account is the difficulty of the “work” that is being processed: that is, the length of time it takes one worker to complete one unit of work.It might be cool to develop some kind of dynamic chunk-sizing logic based on runtime performance.
Conclusion
MCE’s author, Mario Roy has done wonderful job of providing a simple API and fantastic documentation. It’s really easy to get started with a basic automation model like MCE::Grep, and obtain instant speed improvements. There is however, a lot more to MCE such as initialization and shutdown routines, callbacks and sequencing. Be sure to check it out.
Thanks
Thanks to Jeff Thalhammer (Stratopan) for championing this module.
Do you know a module that you’d like us to cover? If so, we’d love to hear from you! Email us at: perltricks.com@gmail.com.
This article was originally posted on PerlTricks.com.
Tags
David Farrell
David is the editor of Perl.com. An organizer of the New York Perl Meetup, he works for ZipRecruiter as a software developer, and sometimes tweets about Perl and Open Source.
Browse their articles
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub
