




Parse Excel with ease using Perl
In the business world, it seems like Excel spreadsheets are everywhere. Recently I had to parse several hundred spreadsheets under a tight deadline for a client. To make matters worse, the spreadsheets were in a mix of Excel 2003 (xls) and 2007 (xlsx) formats. Fortunately I know Perl, and using the Spreadsheet::Read module, it was easy. This article will show you how to use Spreadsheet::Read to parse Excel spreadsheets.
Requirements
You’ll need to install Spreadsheet::Read and a couple of interface modules. Spreadsheet::ParseExcel is an interface for Excel 2003 spreadsheets and Spreadsheet::XLSX is for reading the modern Excel format. You can install all three modules from the terminal using cpan:
$ cpan Spreadsheet::ParseExcel Spreadsheet::XLSX Spreadsheet::Read
Using Spreadsheet::Read
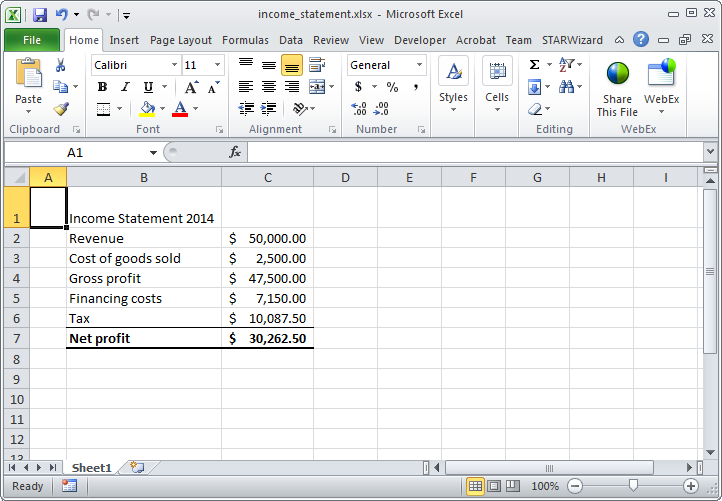
Let’s parse the spreadsheet shown in the cover image, which contains an income statement. Spreadsheet::Read provides a simple, unified interface for reading spreadsheets. It exports the ReadData function which requires a filepath to the spreadsheet:
use Spreadsheet::Read;
my $workbook = ReadData('income_statement.xlsx');
Now $workbook contains the data structure representing the spreadsheet. We can inspect this structure by printing it with Data::Printer:
\ [
[0] {
error undef,
parser "Spreadsheet::XLSX",
sheet {
Sheet1 1
},
sheets 1,
type "xlsx",
version 0.13
},
[1] {
attr [],
B1 "Income Statement 2014",
B2 "Revenue",
B3 "Cost of goods sold",
B4 "Gross profit",
B5 "Financing costs",
B6 "Tax",
B7 "Net profit",
cell [
[0] [],
[1] [],
[2] [
[0] undef,
[1] "Income Statement 2014",
[2] "Revenue",
[3] "Cost of goods sold",
[4] "Gross profit",
[5] "Financing costs",
[6] "Tax",
[7] "Net profit"
],
[3] [
[0] undef,
[1] undef,
[2] 50000,
[3] 2500,
[4] 47500,
[5] 7150,
[6] 10087.5,
[7] 30262.5
]
],
C2 " $ 50,000.00 ",
C3 " $ 2,500.00 ",
C4 " $ 47,500.00 ",
C5 " $ 7,150.00 ",
C6 " $ 10,087.50 ",
C7 " $ 30,262.50 ",
label "Sheet1",
maxcol 3,
maxrow 7
}
]
This shows that $workbook is an arrayref, whose first element describes the file, and subsequent elements represent the individual worksheets. The label key pair contains the worksheet name, access it like this:
$workbook->[1]{label}; #Sheet1
Cells can be referenced using Excel’s grid notation (“A3”) or via standard Perl array access. The different between these is formatting:
$workbook->[1]{C2}; #$ 50,000.00
$workbook->[1]{cell}[3][2]; #50000
So if you need to perform additional processing on the data you’re extracting (such as saving to a database), you probably want to use the {cell} notation, to obtain clean data. With Spreadsheet::Read array indexes begin at 1, so cell “C2” is [3][2].
Perhaps you want to loop through two columns at once and print them? No problem:
for (2..7) {
print "$workbook->[1]{cell}[2][$_]: $workbook->[1]{cell}[3][$_]\n";
}
There are some data points which Spreadsheet::Read does not provide: you cannot access the underlying formula of a cell and the styling data is also not available.
Conclusion
Spreadsheet::Read isn’t just great for command line apps, it has many uses. Unlike the Microsoft .Net interop library, Perl’s Excel interfaces are not single threaded and do not require Excel to be installed to work. Instead Spreadsheet::Read directly parses the Excel file. That makes it possible to process large computing tasks in parallel. Another possible use case is for a spreadsheet upload interface on a web application; Spreadsheet::Read also supports the Libre / Open Office formats as well as CSV text files.
This article was originally posted on PerlTricks.com.
Tags
David Farrell
David is the editor of Perl.com. An organizer of the New York Perl Meetup, he works for ZipRecruiter as a software developer, and sometimes tweets about Perl and Open Source.
Browse their articles
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub
